BioCoder is a challenging bioinformatics code generation benchmark for examining the capabilities of state-of-the-art large language models (LLMs)
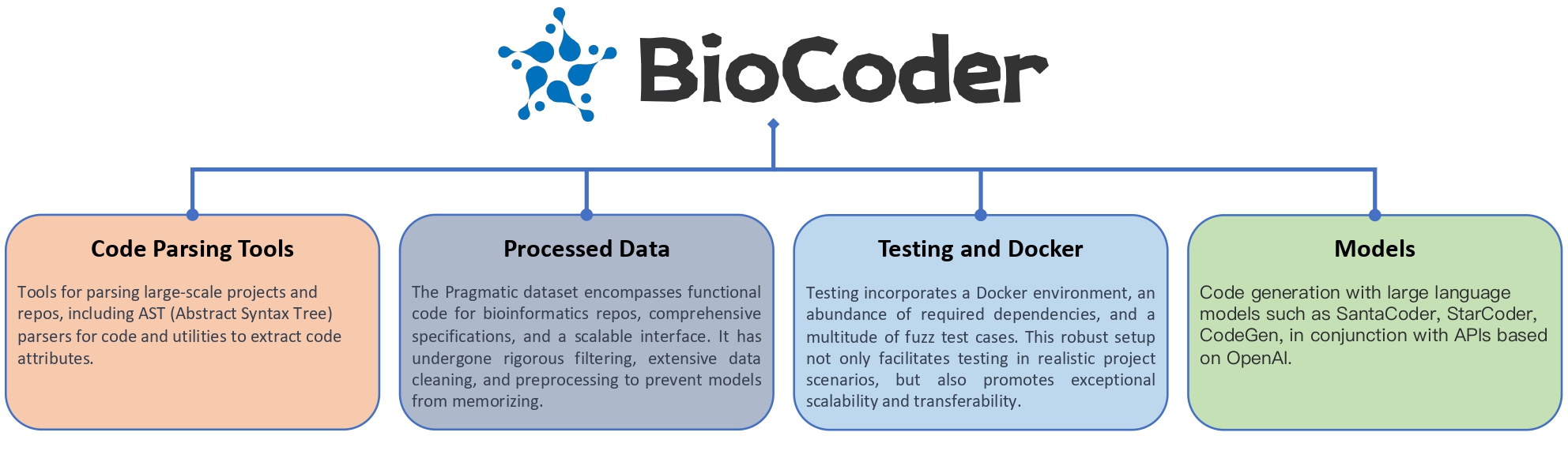
In addition to the dataset, BioCoder also features:
1. A syntax parser for real-world projects, which can be used to extract code snippets from GitHub repositories.
2. An flexible model generation framework that automates the code generation process.
3. A scalable testing framework utilizing both static analysis, manual test cases, and the fuzzing technique, which greatly improves the efficiency of writing test cases.
In addition to the dataset, BioCoder also features:
1. A syntax parser for real-world projects, which can be used to extract code snippets from GitHub repositories.
2. An flexible model generation framework that automates the code generation process.
3. A scalable testing framework utilizing both static analysis, manual test cases, and the fuzzing technique, which greatly improves the efficiency of writing test cases.